
|
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index] [Xen-devel] [PATCH]RFC: VGA accleration using shadow PTE D-bit to construct LFB dirty bitmap
With current
accelerated VGA for qemu-dm, guest can access LFB directly,
however, qemu-dm is not conscious of these accesses to LFB.
The accompanying task is to determine the range of LFB to be redrawn
on guest display window. Current qemu-dm maintains a copy of LFB, and gets the LFB dirty-bitmap through
memcmp. This patch adopts another way to get the LFB dirty-bitmap: one hypercall
to instruct hypervisor to fill the dirty-bitmap. Hypervisor checks the
D-bit of PTEs and updates the dirty-bitmap.
I did some tests to show the benefit of this patch : DB + n Idle winxp linux/DB
guest : running sysbench/DB, 2 vcpus, 512M winxp guest : 2vcpus, 128M(8M shadow)
The
test result show that this patch will bring benefit to our bottleneck dom0 and
the system scalability besides qemu-dm itself.
The
DB throughtput :
1.w/o
patch -- 49% downgrade for 8 winxp guest and 34% downgrade for 4 winxp
guest
2.w/
patch -- <2% downgrade for 8 winxp guest and <1%
downgrade for 4 winxp guest
Following
two charts (refer to the attached file:
result.bmp)show the cpu utilization scatters of dom0 w/ and w/o
patch
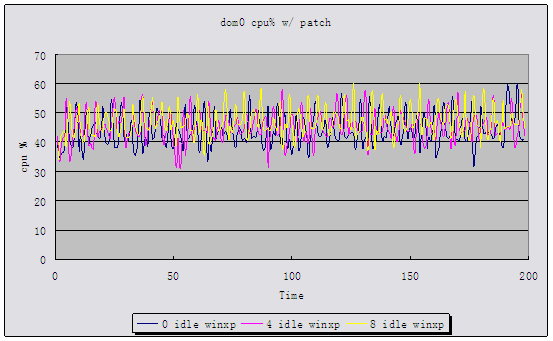 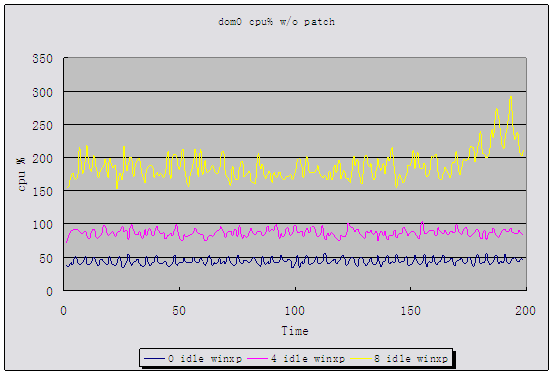 - Xinmei Attachment:
vga.acc.patch Attachment:
result.bmp _______________________________________________ Xen-devel mailing list Xen-devel@xxxxxxxxxxxxxxxxxxx http://lists.xensource.com/xen-devel
|
 |
Lists.xenproject.org is hosted with RackSpace, monitoring our |
{kind=link}