
|
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index] Re: [Xen-devel] [RFC PATCH 2/2] gnttab: refactor locking for better scalability
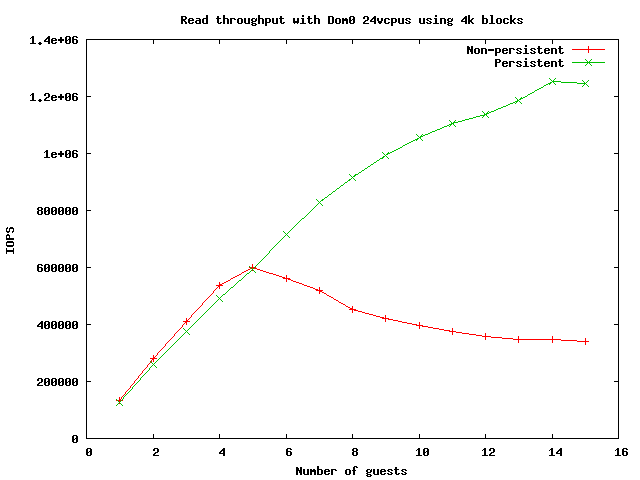
On Tue, Nov 12, 2013 at 05:37:08AM +0000, Keir Fraser wrote: > On 12/11/2013 02:03, "Matt Wilson" <msw@xxxxxxxxx> wrote: > > > + Locking > > + ~~~~~~~ > > + Xen uses several locks to serialize access to the internal grant table > > state. > > + > > + grant_table->lock : rwlock used to prevent readers from > > accessing > > + inconsistent grant table state such as > > current > > + version, partially initialized active table > > pages, > > + etc. > > + grant_table->maptrack_lock : spinlock used to protect the maptrack state > > + active_grant_entry->lock : spinlock used to serialize modifications to > > + active entries > > + > > + The primary lock for the grant table is a read/write spinlock. All > > + functions that access members of struct grant_table must acquire a > > + read lock around critical sections. Any modification to the members > > + of struct grant_table (e.g., nr_status_frames, nr_grant_frames, > > + active frames, etc.) must only be made if the write lock is > > + held. These elements are read-mostly, and read critical sections can > > + be large, which makes a rwlock a good choice. > > Is there any concern about writer starvation here? I know our spinlocks > aren't 'fair' but our rwlocks are guaranteed to starve out writers if there > is a steady continuous stream of readers. Perhaps we should write-bias our > rwlock, or at least make that an option. We could get fancier but would > probably hurt performance. Yes, I'm a little concerned about writer starvation. But so far even in the presence of very frequent readers it seems like the infrequent writers are able to get the lock when they need to. However, I've not tested the iommu=strict path yet. I'm thinking that in that case there's just going to be frequent writers, so there's less risk of readers starving writers. For what it's worth, when mapcount() gets in the picture with persistent grants, I'd expect to see some pretty significant performance degradation for map/unmap operations. This was also observed in [1] under different circumstances. But right now I'm more curious about cache line bouncing between all the readers. I've not done any study of inter-arrival times for typical workloads (much less some more extreme workloads like we've been testing), but lock profiling of grant table operations when a spinlock was used showed some pretty long hold times, which should translate fairly well to decent rwlock performance. I'm by no means an expert in this area so I'm eager to hear the thoughts of others. I should also mention that some of the improvement I mentioned from 3,000 MB/s to 3,600 MB/s was due to avoiding the m2p override spinlock in dom0. > Looks like great work however! Thanks! I'm definitely interested to see some others' experience with these changes. I think that the double_gt_lock() caused a fair bit of contention on the local domain's grant table lock, which explains some of the poor performance with large numbers of vCPUs as seen in [2]. --msw [1] http://scholarship.rice.edu/bitstream/handle/1911/71683/RAM-THESIS.pdf [2] http://xenbits.xen.org/people/royger/persistent_grants/persistent_read24vcpus.png _______________________________________________ Xen-devel mailing list Xen-devel@xxxxxxxxxxxxx http://lists.xen.org/xen-devel
|
 |
Lists.xenproject.org is hosted with RackSpace, monitoring our |
{kind=link}